
わぁ!中国発の話題がここまでバズったのは久しぶり…
実際にはたった5年ぶりだけどね 😆🦠

ここ2週間、DeepSeekに関するニュースと、それがさまざまな分野(技術的・政治的・社会的)に与える影響についての議論が溢れかえっていた。そこで、個人的に面白いと感じた意見をまとめて、より包括的な視点でこの話題を整理してみたら面白いかなと思った。
AI関連の話題では、いつものように「これは我々が知る世界の終焉だ 🤯🔥🤖💀」から「まあ、大したことないでしょ 😑🤷🥱😴」まで、反応は極端に分かれる。
毎日さまざまな情報源からニュースを読んでいると、どのメディアがどの視点を強調しているかで、どれだけ注目されているかがよく分かる。「この中国版スプートニク・ショックで眠れなくなった?」みたいな言い回しをするところもあるしね。
確かにDeepSeekの登場はAI業界全体(さらには世界の市場)に衝撃を与えた。でも、その影響が実際にどのように現れるのかを理解するには、多角的な視点が必要だ。
というわけで、DeepSeekの“瞬間”を捉える4つの視点を紹介しよう ↙️
1️⃣ 技術的視点: DeepSeekの何が新しいのか?
DeepSeekの進歩は、単に米国主導の企業に追いつくことが目的ではなく、AI開発をまったく新しい方向へと導くことにある。いくつかの重要な差別化要因を挙げると:
トレーニング規模と効率性 – これが最も重要なポイントだ。DeepSeekのモデルはパラメータの使用効率が非常に高く、OpenAIやAnthropicと比較してごくわずかな計算コストで競争している。
「わずか」とは、具体的に言うと0.0086%の計算コストのこと。
もし彼らの報告が正しいなら、DeepSeek R1のトレーニング費用は約600万ドル。比較すると、OpenAIは2024年の新モデルのトレーニングに約70億ドルを投じると言われている…もちろん、そのすべてがo1(DeepSeekのR1の推論モデルに相当)に費やされるわけではないが、それでも大きな差だ。
問題は、どうやってこれを実現したのか?ということだ。
これは皮肉な話だ。ニュースを読む側と作る側の視点では、米国の輸出規制がどれほど効果的だったのか、また、先進的なGPUの有無がどれほどのアドバンテージをもたらしたのかは、完全には明らかにならない。
ただ一つ確かなのは、イノベーションは常に道を見つけるということだ。どれだけ社会的に抑制しようとしても、結果として技術は進化してしまう。DeepSeekの研究者たちは、雑草のような存在だ。どれだけ防ごうとしても、強いものは生き残り、気づいたときにはすでに深く根を張っている。つまり、自然の摂理というわけだ。
さらに詳しく知りたいなら、以下の技術レポートをどうぞ:
そうは言っても…
報告されている600万ドルという数字には、過去の研究費用や既存のインフラの利用コストが含まれていない可能性がある。あるXユーザーはこう指摘している:
「600万ドルには、アーキテクチャ、アルゴリズム、データに関する過去の研究やアブレーション実験のコストが含まれていない」と技術論文には明記されている。「それ以外は良かったですか?」という話だ。つまり、すでに数億ドル規模の研究と大規模なコンピュート環境を持っている研究所なら、確かに600万ドルでR1レベルのモデルを訓練できるかもしれないが、それだけでは説明がつかない。
要するに、「600万ドルでChatGPTクラスのモデルを作った!」という話がセンセーショナルに伝えられているが、実際にはその背景に莫大な研究資金とインフラがあるということだ。
それでもなお、
コスト効率の高さに加えて、DeepSeek Coderは、コード生成ベンチマークでGPT-4 Turboと互角に競っている。
また、長文コンテキスト処理の強さも見られ、AnthropicのClaudeモデルと肩を並べる可能性がある。
そして最も重要なのは、DeepSeekがオープンソース戦略を採用していることだ。これは、米国のAI規制を回避しながら、グローバルな開発者にモデルを提供するというユニークなアプローチだ。
この戦略は、DeepSeekの普及を加速させるだけでなく、「世界のAI開発の標準を決める側」に回ることで、最終的に他の企業に対して優位性を持つ可能性がある。
結論: DeepSeekは、OpenAIがデータ蒸留を疑っているように、単なる「GPTクローン」ではない。むしろ、中国がAIのギャップを埋めつつ、ある意味ではリードし始めている証拠なのだ。
2️⃣ 経済的視点:市場はなぜここまで反応したのか?
DeepSeekの登場により、金融市場は即座に反応し、特にAI関連銘柄、特にNVIDIAの株価が大きく下落した。その理由は以下の通り:
投資家の「コスト過剰」への懸念 – これは2024年夏頃からすでに高まっていた。ビッグテック企業がAI開発に莫大な資金を投入し続ける中で、投資家は実際の収益を求め始めていた。
これまでのところ、それを正当化するだけの利益は証明されておらず、現在もなお不透明なままだ。
NVIDIAとAIハードウェアへの圧力 – AIモデルのトレーニングには高価なGPUが必要であり、NVIDIAはここ数年、その需要の急増により莫大な成長を遂げた。
しかし、中国が米国製のチップに依存せずに世界クラスのAIモデルを作れるとしたら、AIインフラ支配に賭けていた企業にとっては悪いニュースとなる。
これまで、「計算資源(compute access)」はAI業界における最大のボトルネックの一つと見なされていた。トップレベルのAIモデルをトレーニングするには、莫大な計算能力が必要であり、資金力のある企業だけがそれを実現できると考えられていた。しかし、DeepSeekの登場によって、この前提が誤りであったことが明らかになった。
この視点を2023年夏の時点で予測していた人がいる ↙️
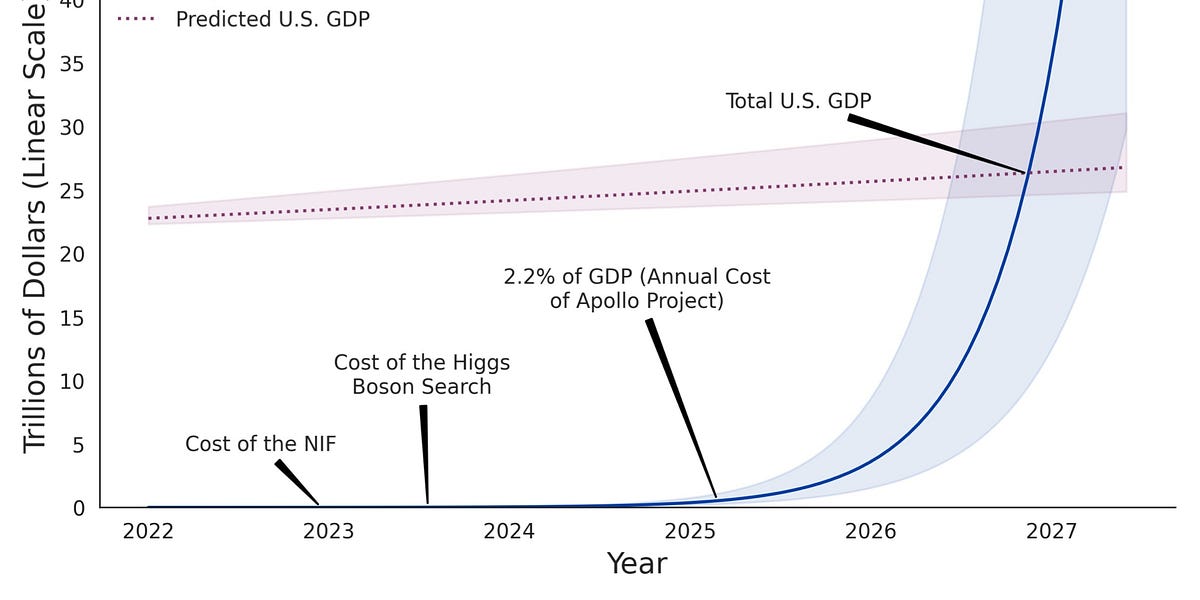
市場は初期のショックから回復しつつあるが、Appleはむしろ勝ち組として浮上している。彼らの「慎重で計画的なAI戦略」は以前は批判されていたが、今となっては評価され始めている。
2024年半ば、人々は「AppleがAI競争に出遅れている」と騒いでいた。
しかし今は、「他のビッグテック企業が何十億ドルも投じている技術を、中国はわずかなコストで実現している」と騒いでいる。
結論: 市場は「不確実性」を嫌う。そして、DeepSeekの登場によって米国主導のAI支配が揺らぐ可能性が生じたことが、不安を引き起こしている。
3️⃣ 国内政治:なぜ米国はこれを「個人的な問題」として捉えているのか?
DeepSeekの登場により、ワシントンや米国主導のテック企業は、自らのAI開発戦略が時代遅れになりつつあることに気付き始めた。その理由は以下の通り:
半導体の輸出規制 – 米国は中国のAI開発を遅らせるために、チップの輸出規制を強化してきた。しかし、DeepSeekの成功を見る限り、その努力は失敗に終わった可能性が高い。
プロジェクト・スターゲート – DeepSeekの登場と時を同じくして、トランプ政権はOpenAI、SoftBank、MGX、Oracleと共同で5000億ドル規模のAIインフラ投資計画を発表した。
しかし、その金額はすでに「バカげている」と言われており、イーロン・マスクですら「詐欺だ」と批判している。
AI開発の「将来性を確保する」ためのインフラ投資という理屈は理解できるが、中国が「ガレージで作れる」レベルのものに数千億ドルを投じることに意味があるのかという疑問が生じている。
結論: 米国政府と米国主導のテック企業は、自分たちの競争優位性の前提について、本気で見直す必要がある状況に直面している。
私たちは、AIの未来が米国主導で進むとなんとなく信じていたのかもしれない。
「まぁ、仮にAIに支配される未来が来るとしても、せめて**"Made in America"** のAIであってほしいよな」🇺🇸🤣😩😳
しかし、今やそのコントロールすら揺らいでいるように見える。
この状況を象徴する「最高に気まずくて笑える曲」があるんだけど、まさにこの雰囲気を完璧に表現している気がする…
要するに、これまで「快適なキャデラック」に乗って、米国のAI支配を疑うことなく進んできた。しかし、DeepSeekの登場は「お前ら、ちょっと現実見ろよ」と言わんばかりの出来事だった。
これは「痛みを伴う祝福」のようなものであり、最初はショックかもしれないが、最終的には米国のAI戦略の自己認識と競争力の向上につながるかもしれない。
4️⃣ 国際政治:DeepSeekは「典型的な中国の動き」なのか?
子どもの頃、おもちゃをひっくり返すと「Made in China」と書かれているのをよく見た。
当然、「なぜ?」という疑問が浮かぶ。
:max_bytes(150000):strip_icc()/INV_ChinaChipManufacturing_GettyImages-1917942474-adc957040449428b8a3e61abcc594f01.jpg)
答えはシンプルだ。
世界が自由貿易を前提に動き、貨物船や航空機などの物流インフラが整備されている現代において、圧倒的に安価な商品を市場に大量供給すれば、時間とともに他国の国内生産者は淘汰される。
中国には、次のような強みがある:
低賃金労働力が豊富
通貨の価値を意図的に抑え、輸出競争力を確保
政府の積極的な製造業支援と、規制の緩さ
例えば、Tシャツを1ドルで売るためには、原材料の調達、縫製、物流のコストを合計しても1ドル未満にする必要がある。米国ではコストが高すぎて、そんな価格では競争できない。
結果として、最も安く製造できる場所に生産が集中する。そして、それはたとえ米国企業であっても例外ではない。
「Designed in the US, Made in China」
極端な話、
アメリカのデザイナーが時給20ドルで製品をデザイン
そのデザインデータを中国に送信
中国の工場が1万個を1個0.01ドルで製造
船便でロサンゼルスまで100ドルで輸送
それを我々が1個100ドルで購入
細かい計算は抜きにしても、流れは明らかだ。
プラスチック製品や衣類などの日用品の生産手段を支配するのは1つの話だが、技術産業でも同じことが起こるのか?
AIの発展には当然、ハードウェア(半導体など)が必要だ。しかし、それだけではなく、高度なエンジニアリング人材も不可欠だ。歴史的に見ても、優秀な技術者を集めた企業がテクノロジー市場を支配してきた。そして、最も高い給与と生活水準を提供できる国が、その人材を引き寄せる傾向がある。
だからこそ、DeepSeekの登場は衝撃的だ。これまでの「常識」を覆すような動きだからだ。
DeepSeekは政府機関ではない——でも
ただし、TikTokの件を見てもわかるように、中国では「民間企業」と「政府」の境界は非常に曖昧だ。
いくつか考慮すべきポイントがある:
国家支援型のAIエコシステム – DeepSeekが「民間企業」であるとしても、中国のAI企業は共産党の厳しい管理下にあり、国家資金の恩恵を受けている。
AIは地政学的な武器 – 中国はAIを経済・軍事競争の中心と位置づけている。
その最終目標は、「技術的主権」—つまり、米国の半導体や技術革新への依存からの脱却にある。
これは、過去のアメリカの覇権を考えれば、ある意味当然の動きだ。
シリコンバレー依存の克服 – 中国のトップAIモデルが米国製チップやクラウドサービスを必要としなくなれば、米国は国際政治における重要な交渉手段を失う。
これまでは、「最新のAI技術を使いたければ、米国と協力せよ」という暗黙のルールがあった。
しかし、もし中国が独自の技術スタックを確立し、他の国々もそれを採用し始めたら?
そうなれば、米国の影響力は大幅に低下する。
結論: DeepSeekの成功は、単なる1企業の話ではなく、中国の国家戦略の一環として見るべきだ。直接的な政府プロジェクトではないかもしれないが、中国が長年取り組んできた「米国の技術覇権に対抗する動き」の延長であることは間違いない。
結局のところ、これはただの一時的なニュースではない。
DeepSeekの登場は、AIの勢力図が「本当に多極化し始めた」ことを示す出来事だ。これにより、いくつかの重要な問いが浮かび上がる:
米国はAIのリーダーシップを維持できるのか?
チップ輸出規制は…本当に機能しているのか?
グローバル企業は、中国のAI発展にどう対応すべきなのか?
この業界は、毎日何か新しいことが起こる。まだまだ目が離せない。